The PIVOT operation is like a handy tool for changing how data looks. When using it, you often pair it with functions like SUM or MAX to crunch the numbers. In this article, we will learn about PIVOT in SQL, along with examples.
What is PIVOT in SQL?
The PIVOT operator in SQL is used to transform data from rows into columns. Pivoting involves the rotation of data from a row-wise orientation to a column-wise one.
This transformation is particularly useful when dealing with data that needs to be presented in a different format for reporting or analysis. SQL's PIVOT operator simplifies this process by allowing us to convert aggregated values into columns.
It's particularly useful when you want to switch from seeing data row by row to seeing it in columns. This makes the information clearer, especially for reports or analysis.
You can set it up in two ways: either with fixed column names or dynamic ones that adapt to your data. The basic idea is to say which column you want to pivot, what you want to do with the numbers (like adding them up), and then list the unique values that will become the new columns.
For example, imagine a sales table; you could use PIVOT to show the total sales for each product on specific dates.
Let’s look at the syntax of using pivot:
SELECT [pivot_column], [aggregate_function]([values_column]) FROM [source_table] PIVOT ( [aggregate_function]([values_column]) FOR [pivot_column] IN ([value1], [value2], ... ,[valueN]) ) AS [pivot_table];
Let's break down the components:
- pivot_column: This is the column in the source table that will become the column headers in the pivoted result.
- aggregate_function: The function used to aggregate values in the values_column. Common aggregate functions include SUM, COUNT, AVG, etc.
- values_column: The column containing the values to be aggregated and pivoted.
- source_table: The original table containing the data.
- pivot_table: The alias for the resulting pivoted table.
[value1], [value2], ..., [valueN]: The unique values from the pivot_column that will become the new column headers in the pivoted result.
Pivoting in SQL Example
Let's walk through a simple example to illustrate how the PIVOT operator works in SQL Server.
Consider a table named Sales with the following structure:
Table: Sales
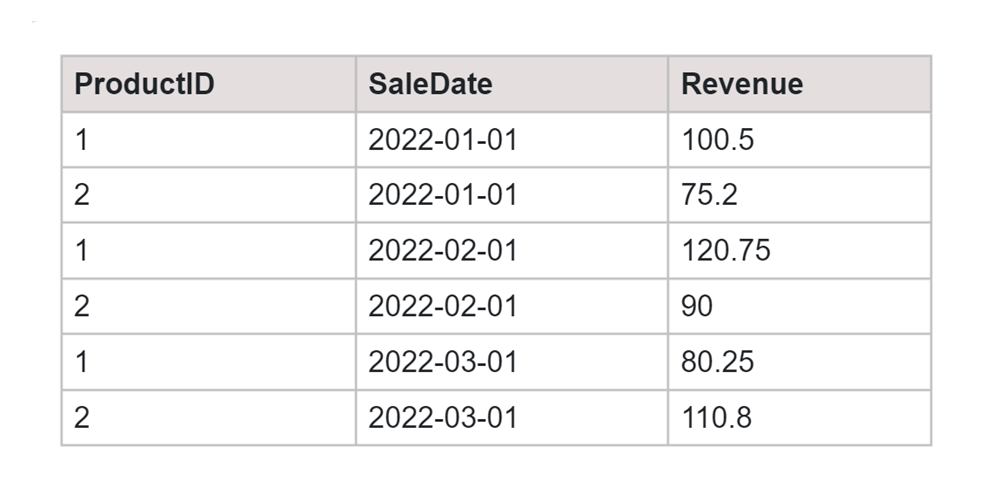
SQL Query:
SELECT * FROM ( SELECT ProductID, SaleDate, Revenue FROM Sales ) AS SourceTable PIVOT ( SUM(Revenue) FOR SaleDate IN ([2022-01-01], [2022-02-01], [2022-03-01]) ) AS PivotTable;
Output:
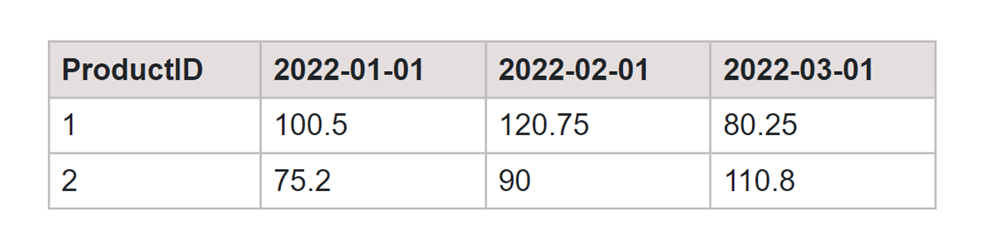
This query uses the PIVOT operator to aggregate the Revenue values for each ProductID on specific sale dates, transforming the data into a more readable format. Adjust the sale dates in the FOR SaleDate IN (...) section based on your actual data.
Dynamic Pivoting in SQL Example
Dynamic pivoting in SQL provides a powerful and flexible approach to transform data dynamically based on the actual values within a column. Unlike static pivoting, where the pivot columns are predefined, dynamic pivoting allows you to pivot data based on the distinct values present in a particular column.
This can be particularly useful when dealing with datasets where the categories or attributes may change over time.
Table: FeesPaid
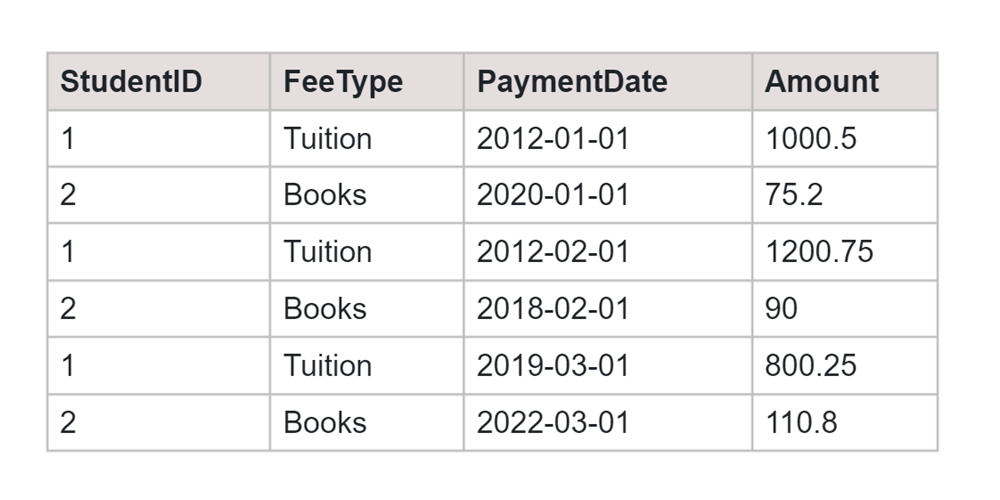
SQL Query:
DECLARE @DynamicPivotColumns NVARCHAR(MAX); DECLARE @DynamicPivotQuery NVARCHAR(MAX); SELECT @DynamicPivotColumns = STRING_AGG(DISTINCT QUOTENAME(FeeType), ', ') FROM FeesPaid; SET @DynamicPivotQuery = SELECT StudentID, ' + @DynamicPivotColumns + ' FROM ( SELECT StudentID, FeeType, PaymentDate, Amount FROM FeesPaid ) AS SourceTable PIVOT ( SUM(Amount) FOR FeeType IN (' + @DynamicPivotColumns + ') ) AS PivotTable; EXEC sp_executesql @DynamicPivotQuery;
Output:
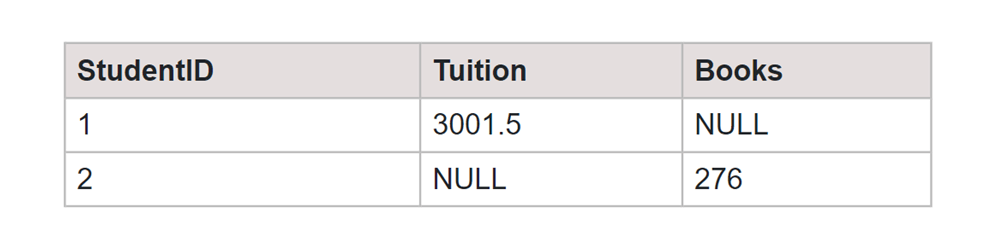
In this output:
- Each row represents a unique StudentID.
- Columns represent different FeeTypes (in this case, 'Tuition' and 'Books').
- Values in the cells represent the total amount paid by each student for the corresponding fee type.
Pivoting Rows to Columns
This process is particularly useful when transitioning from a row-wise format, where each record is a separate row, to a column-wise arrangement, where specific values become distinct columns.
In essence, it simplifies data representation, making it more accessible for analysis and reporting. This transformation is achieved through conditional aggregation or specialized pivot functions available in certain SQL databases.
Let us understand this through an example:
Table:EmployeeSalaries
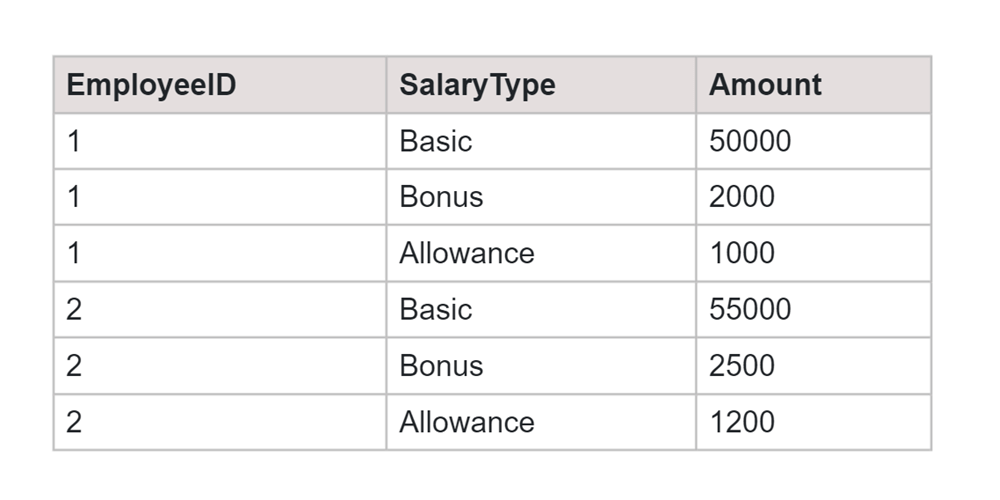
SQL Query:
SELECT * FROM ( SELECT EmployeeID, SalaryType, Amount FROM EmployeeSalaries ) AS SourceTable PIVOT ( MAX(Amount) FOR SalaryType IN ([Basic], [Bonus], [Allowance]) ) AS PivotTable;
Output:
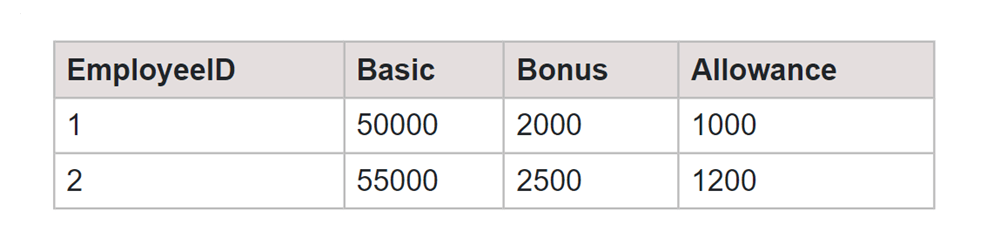
This SQL query uses the PIVOT operation to transform data from the EmployeeSalaries table. It selects EmployeeID, SalaryType, and Amount, and then pivots the Amount values based on distinct SalaryType categories such as [Basic], [Bonus], and [Allowance].
This rearranges the original rows into a format where each EmployeeID has specific columns for different salary types, displaying the maximum Amount values.
Conclusion
In summary, pivoting in SQL is a useful technique that transforms how data is presented, making it easier to understand and analyze. This process involves changing data from a row-based to a column-based structure, offering a clearer view.
By using aggregate functions like SUM, MAX, or AVG, we can summarize information within these new columns. Dynamic pivoting is a flexible approach, automatically adjusting to changes in the dataset. SQL's PIVOT operation provides a straightforward syntax, making it accessible for practitioners.