Rank functions play a key role in identifying the positions of certain data in SQL. Not only can we gain insights into the relational database, but we can also retrieve information that is hidden in the table. Through this article, you will not just be able to understand RANK() functions in SQL but also learn how to implement them in real-world scenarios.
What is the RANK() Function in SQL?
The SQL RANK() function uses techniques to assign a specific ranking number to rows within a table based on the given condition.
Often there are cases when the RANK() function finds multiple values with the same rank or position, then the function gives priority based on different columns in nomenclature. Thus, the RANK() function optimizes data to deal with duplicate data.
For example, the RANK() function can be used to determine the rank of employees within each department based on their salary or the rank of students based on their examination results. The output table enhances decision-making in scenarios where understanding the hierarchy of data is key.
These functions help the user to identify the hierarchy of the database values and apply strategic decisions based on them.
Syntax:
SELECT column1, column2 RANK() OVER ( PARTITION BY partition_column1, partition_column2 ORDER BY order_column1 (ASC or DESC), order_column2 (ASC or DESC) ) AS rank_column FROM table_name;
Let us understand the use of the RANK() function using PARTITION BY AND ORDER BY through an example.
Table: Exam_Results
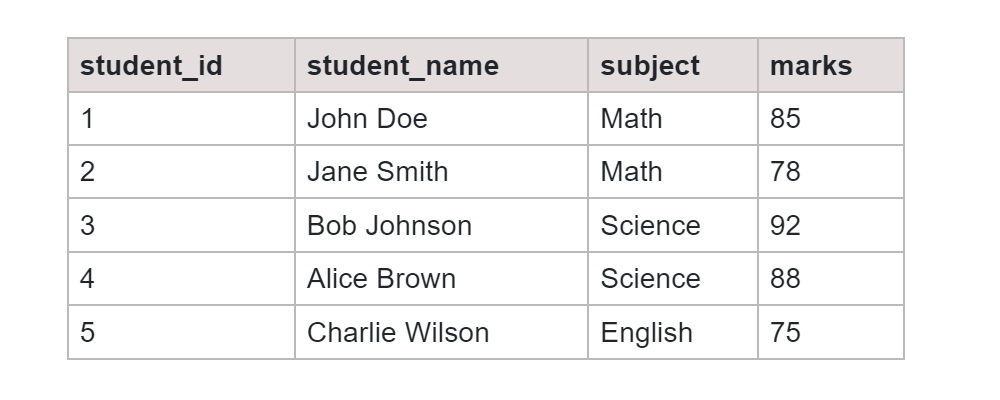
SQL Query:
SELECT column1, column2 RANK() OVER ( PARTITION BY partition_column1, partition_column2 ORDER BY order_column1 (ASC or DESC), order_column2 (ASC or DESC) ) AS rank_column FROM table_name;
Output:
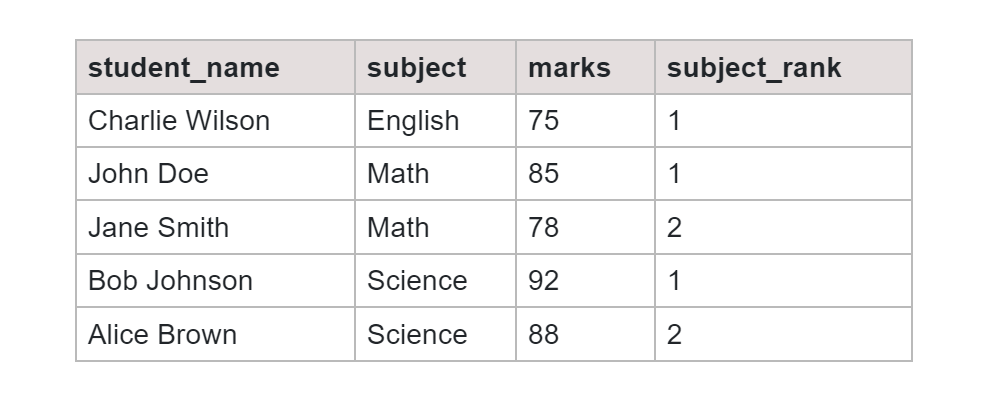
The output here shows the details of the students based on their ranks in their respective subjects.
What is the DENSE_RANK() Function?
The DENSE_RANK() function is an efficient tool that works around the ranking function approach. This continuous ranking is particularly helpful in situations where a clear and structured hierarchy is important for data interpretation. The PARTITION BY clause is used to predefine the set of rankings in the rows.
There are no two values that have the same rank, it makes sure to assign unique and distinct ranking values to the group of rows. The RANK() Function and DENSE_RANK(), produce a distinct environment by maintaining a sequential rank status of the data.
Syntax:
SELECT column1, column2, DENSE_RANK() OVER (ORDER BY order_column1 [ASC or DESC], order_column2 [ASC or DESC]) AS dense_rank_column FROM table_name;
Table: Employees_Salary
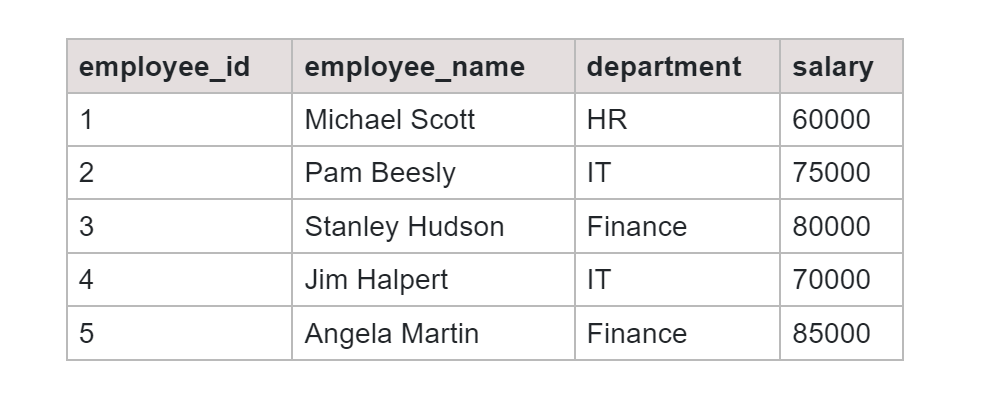
SQL Query:
SELECT employee_id, employee_name, department, salary, DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS department_dense_rank FROM employee_salary;
Output:
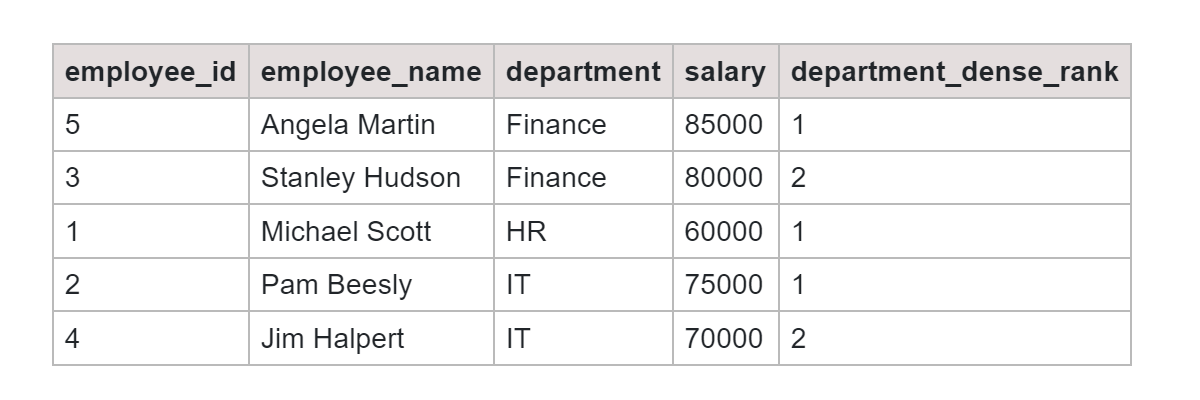
The output shows us a list of employees along with their respective departments, salaries, and the assigned dense rank based on their salary.
Real-World Scenarios of the RANK() Function
Here are some real-life applications of these functions in SQL:
- The RANK() functions are often used to compare different products based on their performance and sales information.
- To determine the position of students in an educational center based on the marks scored by them.
- Used as a key performance indicator in Human Resource Departments to determine the employee's performance and rank them.
- In sports analytics, these functions play a pivotal role in determining the position of players and applying key strategic decisions.
- Market Analysts use these functions to compare different products in the market to benchmark them
Difference between ROW_NUMBER(), RANK() and DENSE_RANK()
The ROW_NUMBER(), RANK(), and DENSE_RANK() are window functions in SQL used for assigning a unique value to each row based on a given order.
The difference is how they work around data interrelation in the table. ROW_NUMBER() assigns a unique integer to each row, starting from 1, RANK() also assigns a unique integer but leaves spaces in the numbering, ensuring that no two values are of the same rank. Whereas DENSE_RANK() is quite similar to RANK(), but the difference is that it does not leave any gap in the data.
Conclusion
Overall we explored the applications of the rank functions, like RANK() and DENSE_RANK() in SQL. They are used when data organization and arrangement come into play. The RANK() function is known for handling values with gaps, while the DENSE_RANK() function works around a continuous sequence of ranks.