Ever wondered how databases keep track of unique things? COUNT and DISTINCT are powerful tools that help us figure out just that. In simple? terms, it is like counting distinct items in a séa of data. This blog will explain what COUNT DISTINCT in SQL is, why it is important, and how we can use it to find important information in our databases.
What is COUNT DISTINCT in SQL?
Let us understand the use of the COUNT Function using an example, imagine you are organizing a collection of books in a library.
Each book has a different genre, and you are curious about how many distinct genres there are. Now, if you us? COUNT DISTINCT, it is like having a librarian who only counts each genre once, regardless of how many books there are in each category. This way, you get a quick and precise answer to how many unique types of genres you have in your library.
In the context of databases, this is super handy when dealing with large sets of information. You might have a massive list of transactions, but you're interested in knowing how many different product categories were involved, not the total number of transactions.
COUNT DISTINCT in SQL allows you to narrow down your focus to the unique elements, providing a clear picture of the diversity in your data.
What is Count(*) Function?
In SQL, the COUNT(*) function is a l command used to determine the total number of rows within a table. It acts as a universal counter, impartial to the contents of each row, focusing only on providing a quick and efficient tally.
This function is incredibly handy, serving as a fundamental tool for going through the overall dataset without going into the specifics of individual records.
Syntax:
SELECT COUNT(*) AS TotalRowCount FROM TableName;
In the "Students" table below, we will employ the COUNT function to determine the overall count of students.
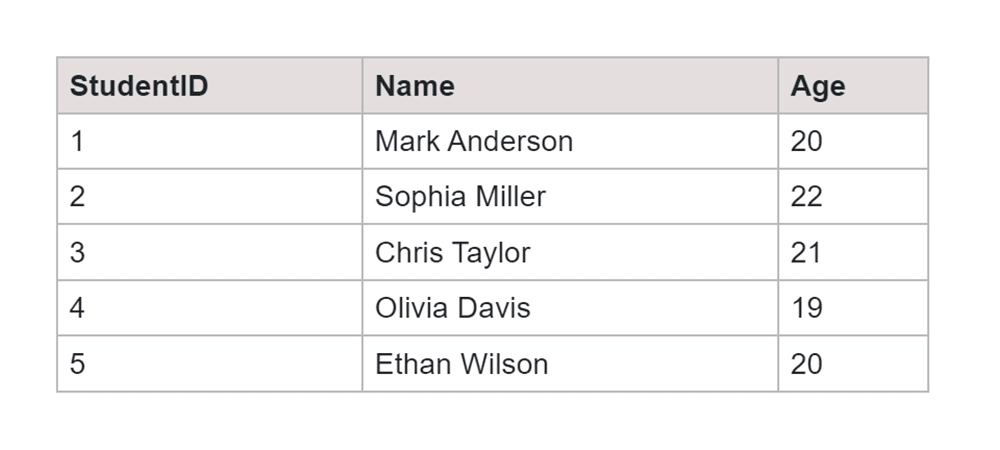
SQL Query:
SELECT COUNT(*) AS TotalStudents FROM Students;
Output:

COUNT(DISTINCT) in SQL
Unlike regular counting, which counts everything, COUNT(DISTINCT) helps us figure out how many different things there are in a specific column of our data. It is a bit like going through a list of colors and wanting to know how many distinct colors you have without counting the same color twice.
For example, if you have different fruits and you want to know how many different types of fruits there are, you'd use COUNT(DISTINCT FruitType). This function looks at the "FruitType" column and tells you the total count of unique fruit types in your table.
In simpler terms, COUNT(DISTINCT) is like a data finder that helps us quickly find out how many different and special things we have in our data, making it a handy tool for exploring diversity within a dataset.
Syntax:
SELECT COUNT(DISTINCT column_name) AS output_column FROM TableName;
For instance, let's consider a table containing information about courses. Our goal is to determine the number of distinct instructors associated with the institute.
SQL Query:
SELECT COUNT(DISTINCT Instructor) AS UniqueInstructors FROM Courses;
Output:

WHERE CLAUSE in COUNT Function
In SQL, the "WHERE" clause significantly enhances the functionality of the COUNT function, introducing a layer of precision to the counting process.
By default, COUNT gives us a broad total of all rows in a table. However, when we incorporate the "WHERE" clause, it becomes a dynamic tool for selective counting. This clause acts as a filter, allowing us to count only those rows that meet specific conditions or criteria.
It introduces the concept of conditional counting, enabling us to focus our analysis on particular subsets of data. The "WHERE" clause becomes particularly useful when we want tailored results, as it empowers us to count rows based on predefined conditions,
Syntax:
SELECT COUNT(*) AS output_column FROM TableName WHERE condition;
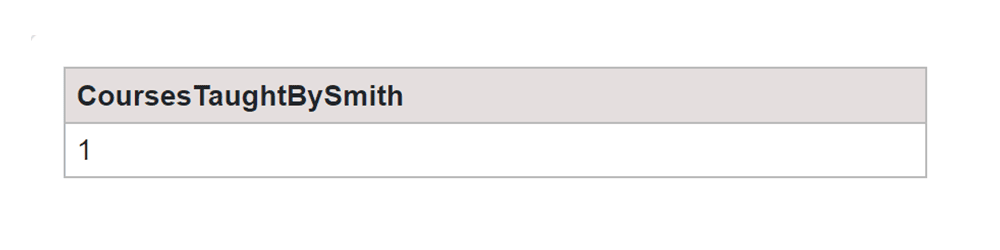
We will employ the "WHERE" clause in the COUNT function to find out how many courses are taught by Professor Smith.
SQL Query:
SELECT COUNT(*) AS CoursesTaughtBySmith FROM Courses WHERE Instructor = 'Professor Smith';
Output:
Common Challenges when using COUNT and DISTINCT
Here are some challenges you can enter while doing this:
- Sometimes, the same information appears more than once in a column, affecting accurate counting. Regularly check for and eliminate duplicate entries to ensure precise counts.
- The same information may appear more than once in a column, affecting accurate counting. Check for and eliminate duplicate entries to ensure precise counts.
- Rows with null values may be overlooked, impacting the total count. So, Include conditions in your query to account for null values and ensure a comprehensive count.
- Counting distinct values in large datasets can be time-consuming. Optimize database performance by indexing columns and using efficient query structures for faster and more responsive results.
You can now learn how to find duplicate columns in SQL.
Conclusion
Now you have known all use cases of COUNT DISTINCT in SQL. W? hav? l?arn?d that COUNT giv?s us a straightforward way to tally up everything, providing a broad view of our data. On the other hand, COUNT DISTINCT steps in as th? detecting, allowing us to pinpoint and count only the unique elements, adding ease of access to our analysis.